


An AI system has reached human level on a test for ‘general intelligence’. Here’s what that means
- Written by: Michael Timothy Bennett, PhD Student, School of Computing, Australian National University

A new artificial intelligence (AI) model has just achieved human-level results[1] on a test designed to measure “general intelligence”.
On December 20, OpenAI’s o3 system scored 85% on the ARC-AGI benchmark[2], well above the previous AI best score of 55% and on par with the average human score. It also scored well on a very difficult mathematics test.
Creating artificial general intelligence, or AGI, is the stated goal of all the major AI research labs. At first glance, OpenAI appears to have at least made a significant step towards this goal.
While scepticism remains, many AI researchers and developers feel something just changed. For many, the prospect of AGI now seems more real, urgent and closer than anticipated. Are they right?
Generalisation and intelligence
To understand what the o3 result means, you need to understand what the ARC-AGI test is all about. In technical terms, it’s a test of an AI system’s “sample efficiency” in adapting to something new – how many examples of a novel situation the system needs to see to figure out how it works.
An AI system like ChatGPT (GPT-4) is not very sample efficient. It was “trained” on millions of examples of human text, constructing probabilistic “rules” about which combinations of words are most likely.
The result is pretty good at common tasks. It is bad at uncommon tasks, because it has less data (fewer samples) about those tasks.

Until AI systems can learn from small numbers of examples and adapt with more sample efficiency, they will only be used for very repetitive jobs and ones where the occasional failure is tolerable.
The ability to accurately solve previously unknown or novel problems from limited samples of data is known as the capacity to generalise. It is widely considered a necessary, even fundamental, element of intelligence.
Grids and patterns
The ARC-AGI benchmark tests for sample efficient adaptation using little grid square problems like the one below. The AI needs to figure out the pattern that turns the grid on the left into the grid on the right.
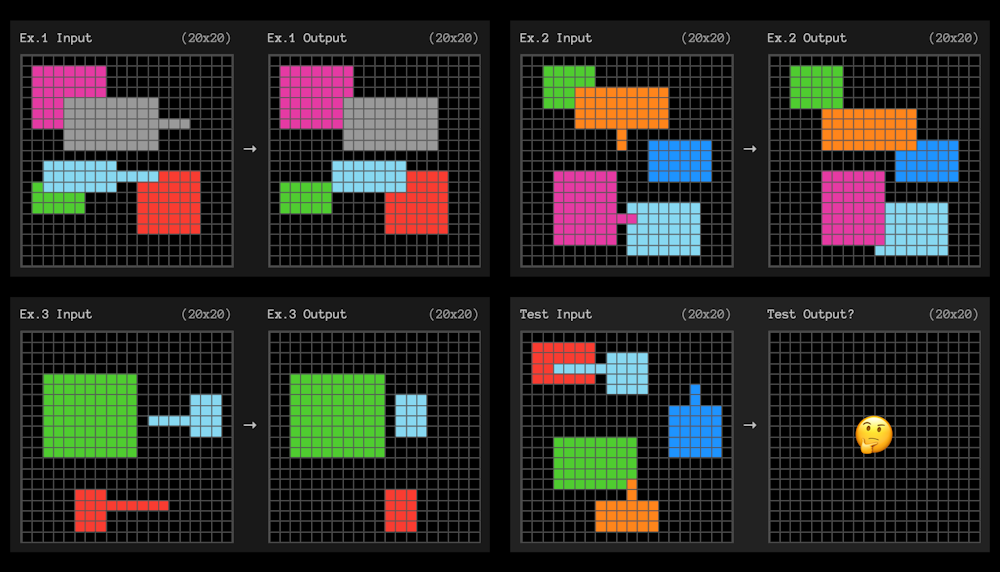 An example task from the ARC-AGI benchmark test. ARC Prize[4]
An example task from the ARC-AGI benchmark test. ARC Prize[4]
Each question gives three examples to learn from. The AI system then needs to figure out the rules that “generalise” from the three examples to the fourth.
These are a lot like the IQ tests sometimes you might remember from school.
Weak rules and adaptation
We don’t know exactly how OpenAI has done it, but the results suggest the o3 model is highly adaptable. From just a few examples, it finds rules that can be generalised.
To figure out a pattern, we shouldn’t make any unnecessary assumptions, or be more specific than we really have to be. In theory[5], if you can identify the “weakest” rules that do what you want, then you have maximised your ability to adapt to new situations.
What do we mean by the weakest rules? The technical definition is complicated, but weaker rules are usually ones that can be described in simpler statements[6].
In the example above, a plain English expression of the rule might be something like: “Any shape with a protruding line will move to the end of that line and ‘cover up’ any other shapes it overlaps with.”
Searching chains of thought?
While we don’t know how OpenAI achieved this result just yet, it seems unlikely they deliberately optimised the o3 system to find weak rules. However, to succeed at the ARC-AGI tasks it must be finding them.
We do know that OpenAI started with a general-purpose version of the o3 model (which differs from most other models, because it can spend more time “thinking” about difficult questions) and then trained it specifically for the ARC-AGI test.
French AI researcher Francois Chollet, who designed the benchmark, believes[7] o3 searches through different “chains of thought” describing steps to solve the task. It would then choose the “best” according to some loosely defined rule, or “heuristic”.
This would be “not dissimilar” to how Google’s AlphaGo system searched through different possible sequences of moves to beat the world Go champion.
 In 2016, the AlphaGo AI system defeated world Go champion Lee Sedol. Lee Jin-man / AP[8]
In 2016, the AlphaGo AI system defeated world Go champion Lee Sedol. Lee Jin-man / AP[8]
You can think of these chains of thought like programs that fit the examples. Of course, if it is like the Go-playing AI, then it needs a heuristic, or loose rule, to decide which program is best.
There could be thousands of different seemingly equally valid programs generated. That heuristic could be “choose the weakest” or “choose the simplest”.
However, if it is like AlphaGo then they simply had an AI create a heuristic. This was the process for AlphaGo. Google trained a model to rate different sequences of moves as better or worse than others.
What we still don’t know
The question then is, is this really closer to AGI? If that is how o3 works, then the underlying model might not be much better than previous models.
The concepts the model learns from language might not be any more suitable for generalisation than before. Instead, we may just be seeing a more generalisable “chain of thought” found through the extra steps of training a heuristic specialised to this test. The proof, as always, will be in the pudding.
Almost everything about o3 remains unknown. OpenAI has limited disclosure to a few media presentations and early testing to a handful of researchers, laboratories and AI safety institutions.
Truly understanding the potential of o3 will require extensive work, including evaluations, an understanding of the distribution of its capacities, how often it fails and how often it succeeds.
When o3 is finally released, we’ll have a much better idea of whether it is approximately as adaptable as an average human.
If so, it could have a huge, revolutionary, economic impact, ushering in a new era of self-improving accelerated intelligence. We will require new benchmarks for AGI itself and serious consideration of how it ought to be governed.
If not, then this will still be an impressive result. However, everyday life will remain much the same.
References
- ^ achieved human-level results (arstechnica.com)
- ^ ARC-AGI benchmark (arcprize.org)
- ^ Bianca De Marchi / AAP (photos.aap.com.au)
- ^ ARC Prize (arcprize.org)
- ^ theory (link.springer.com)
- ^ described in simpler statements (link.springer.com)
- ^ believes (arcprize.org)
- ^ Lee Jin-man / AP (photos.aap.com.au)










